CraneScript 是一种数据流脚本语言.
数据流图是软件系统建模的图形方法之一。 在数据流模型中,一个软件系统被简化为由数据、数据处理模块和数据在数据处理模块间的传递,即数据流三个基本要素构成。 构成软件系统的各个功能被数据分隔成一个一个孤立节点,每个模块仅依赖于它的输入数据,当输入数据到达时,功能模块开始处理数据,并产生输出数据。 整个软件系统的功能由数据流动的逻辑来体现。 在数据流模型中,模块与模块之间不存在耦合,模块由数据来驱动,完全异步运行。 数据流架构是多数大型分布式异步系统以及超算系统软件采用的主流架构。 而数据流编程语言则是一种通过以编程的方式,将数据流架构引入软件开发中以简化软件开发中复杂的结构设计的尝试。
CraneScript是一种软件的数据流架构的代码描述。 从代码实现的角度出发,craneScript对传统数据流图进行了具化和增强,补充了数据类型、模块接口等的详细定义,扩展了数据流子模块, 使得这样的代码描述可以作为脚本被解释器解释运行。 同时,craneScript也可以被看作增强的数据流图(简称为craneFlow)的文本存储格式,可以通过craneFlow数据流图编辑软件进行可视化的编辑。
一个典型的 "hello world" craneScript 脚本如下:
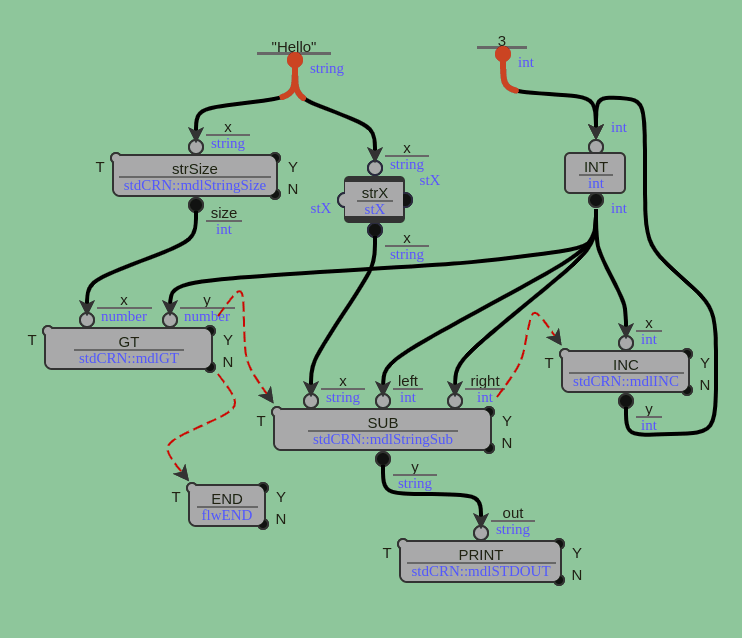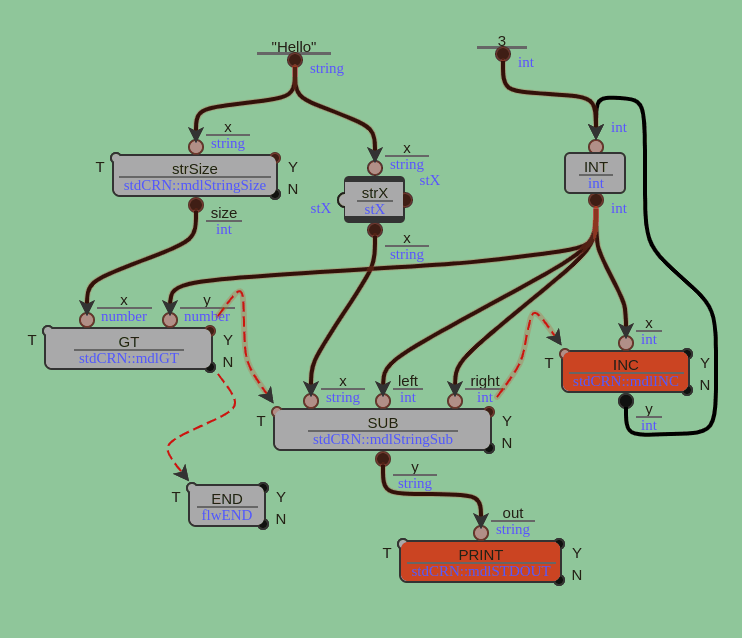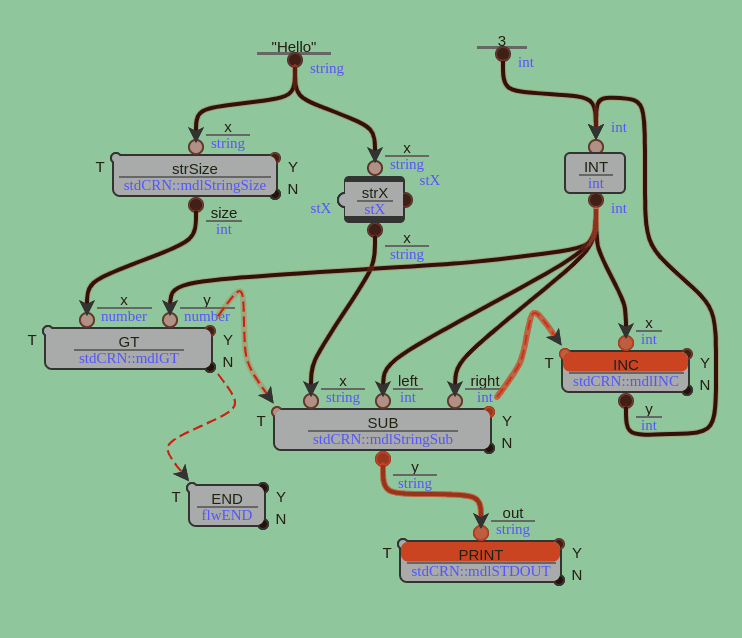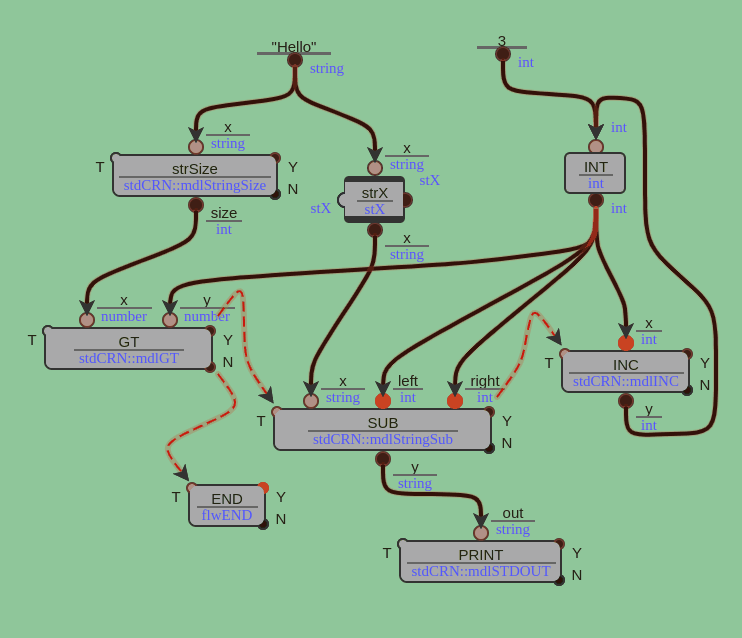
复杂一点,将"hello world!"逐字符打印输出,会得到如下代码。
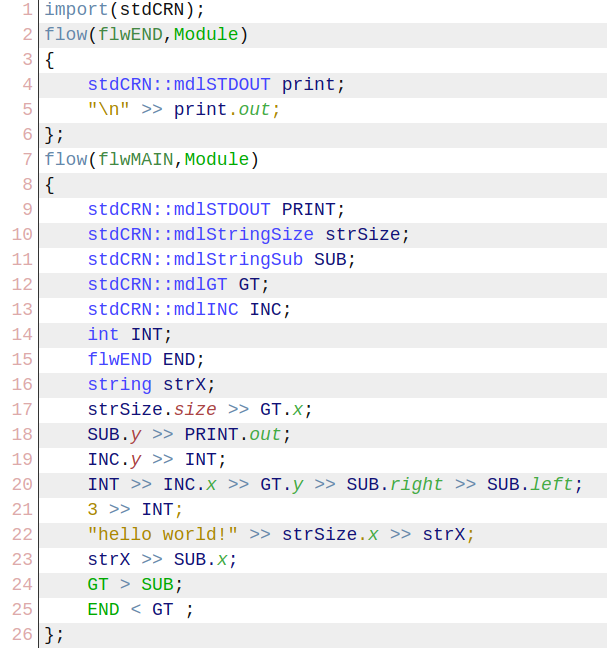
同时,在craneScript中,此代码也是一张细化了数据类型和模块接口的数据流图.
CraneScript的设计初衷是C++的数据流框架,所以在语法的设计保持了对C++的兼容,多数的craneScript的关键字沿用了C++的关键字。
| $ | // | ///* | //*/ | #include | import | struct | module | flow | flwMAIN | thread |
| char | short | int | long | float | double | unsigned | number | string | any | array |
| * | . | , | ; | () | [] | {} | <> | " | ' | > |
| < | >> | << | INP | IOP | OUTP |
"$": 保留关键字,用于标识以“$”开头的未来需要扩充的关键字。
"//":用于标识一个注释行。
"///*" 和 "//*/": 用于标识一个多行的注释块。
".": 用于数据的成员或模块的接口提取。
";": 用于标识一个代码行结束。
"{" 和 "}": 用于标识一个结构体、模块或数据流模块的主体。
其他关键字参见后续相应章节。
CraneScript是一个强类型语言。 CraneScript提供了一组基本类型,并支持用户自定义结构体。 CraneScript同时还提供了容器数组array,用于定义更加复杂的数据类型。 数值类型用于声明数据变量,结构体成员或模块接口类型。
CraneScript提供了几乎全部的C/C++中的基本数值类型。
| 类型 | 长度 |
|---|---|
| char | 8 bits |
| unsigned char | 8 bits |
| short | 16 bits |
| unsigned short | 16 bits |
| int | 32 bits |
| unsigned int | 32 bits |
| long | 32/64 bits,依赖系统版本 |
| unsigned long | 32/64 bits,依赖系统版本 |
| float | 32 bits |
| double | 64 bits |
CraneScript支持四种类型的立即数.
| 立即数 | 格式 |
|---|---|
| char | 以单引号标记的单字符,如: 'h'; 或十六进制表示,如: '\xFF'(字母部分需大写) |
| string | 双引号标记的字符串,如:"hello world" |
| int | 整数值,如:10 |
| double | 浮点数值,如:10.1 or 123.456 |
关键字struct用于声明一个结构体。结构体的仅支持数据成员,且其类型须为已完成前置定义的数据类型。
在craneScript中,数组被设计为一个模板类容器,使用预定义关键字array,数组中的实际数据类型采用模板参数声明。数组允许嵌套。
CraneScript提供了一组用于数组操作的系统模块。
模块用于声明一个数据处理单元,使用关键字module声明。 在craneScript中,模块中的成员被定义为数据端口,共有三种类型:仅输入,仅输出和既输入也输出。分别使用INP,OUTP和IOP标识,格式采用模板格式。
为了更好的支持多态,craneScript提供了两种虚拟数据类型:number和any用于声明数据类型后绑定的端口声明。 其中,number表示该端口接受任一数字类型,any表示接受任意数据类型,而作为输出时则表示可能为其中一种。
CraneScript中有两种流类型,一种是数据流,一种是控制流。
数据流使用流操作符 >>表示. 在craneScript中,>>被定义为具有广播特性的操作符。 一条数据流语句中,可以使用>>连接两个以上的端口,表示数据从最左侧端口出发,广播至右侧所有端口。 所以在一条数据流语句中,语法上,最左侧的端口应使用输出端口,而其他端口应使用输入端口。
在craneScript中,默认的端口间的数据传输均采用传址方式,数据的生命周期由生成该数据的模块管理,而当数据接收方是数据变量或数据结构体变量或结构体成员变量时,因其拥有自己独立的数据空间,此时,数据会产生数据拷贝。
当数据传递工作在传址状态时,一个数据流是两端的数据类型须保持严格一致,而当接收端是数据实体变量时,craneScript允许两端为可进行类型轮换不同类型,脚本引擎会对数据类型进行强制转换后再进行拷贝。
在craneScript中,一个模块运行后会产生两种可能状态:成功态或失败态。 基于此,craneScript定义了两种控制流,分别为正向控制流和反向控制流,对应于成功态和失败态。 其中,正向控制流表示了一种模块运行间的时序依赖关系,使用操作符>表示。 在craneScript中,正向控制流被定义为基于传递的流操作。 即在一个正向控制流语句中,一个模块运行的前置条件是,其左侧所有模块均运行且成功。 反向控制流则被定义为归结式的,反向控制流使用<操作符表示,即反向流语句中,最左侧模块运行的前置条件是右侧任一模块运行失败。
在craneScript中,使用关键字flow定义一个数据流程,这个流程可以表示一个数据流图。 一个数据流程的定义包括两个部分的内容,一个是声明部分,包括该流程的名称和接口定义,其中接口定义使用一个已定义的模块,表示此数据流程实现了一个该模块的实体。 第二个部分是数据流程主体定义:由数据变量声明、模块变量声明、数据流和控制流四种语句构成。
在craneScript中,用户可以使用关键字"#include"引用外部的已有craneScript脚本。
另外,用户也可以使用关键字“import”导入模块的外部实现库。其中最具代表性的是系统预定义模块扩展库"stdCRN”,在"stdCRN"中,系统封装了基本运算、字符处理和一组基本的系统功能模块的实现。
当使用外部引用类型时,需要使用外部源的标识,在craneScript中外部源标识使用外部文件名或库名(不带扩展名),所以在craneScript中,外部源不可以重名。具体的格式为外部源标识+"::"+类型名,与C++的命名空间格式一致。
在一个craneScript脚本中,程序的入口是名为flwMAIN的数据流过程。该过程需要实现一个名为Module的模块的接口。Module为系统默认模块,此模块被定义为无输入,无输出。
与传统的编程语言中将各种基本运算定义为指令集不同,craneScript中数据处理的基本单元是模块,所有的基本运算均是由模块完成的。 CraneScript提供了一组系统预定义模块,包含在stdCRN外部库中,通过"import"语句加载使用。其各模块的接口定义放在"stdCRN.h"中。 在stdCRN库中,包含9小类基本模块,包括:算术操作,位操作,逻辑操作,字符串操作,系统IO操作,文件操作,类型操作和系统杂项。 在各类模块中,需要注意的是,有一部分模块的端口定义为IOP类型,它的输入数据同时也是输出数据,在这些模块中会对输入进行改写,为明确区分,这样的模块名均带有filter字样。
CraneScript中的算术运算模块如下:
| 系统模块 | 定义 | 动作 |
|---|---|---|
| mdlADD |
|
|
| mdlSUB |
|
|
| mdlMUL |
|
|
| mdlDIV |
|
|
| mdlINCfilter |
|
y=y+1 |
| mdlINC |
|
y=x+1 |
| mdlDECfilter |
|
y=y-1 |
| mdlDEC |
|
y=x-1 |
| mdlCntDOWNfilter |
|
|
| mdlCntDOWN |
|
|
| mdlMODfilter |
|
y=y%x |
| mdlMOD |
|
y=x0%x1 |
CraneScript中预定义了如下位操作模块:
| 模块名 | 定义 | 动作(C++) |
|---|---|---|
| mdlAND |
|
y=x0&x1 |
| mdlOR |
|
y=x0|x1 |
| mdlNOT |
|
y=~x |
| mdlXOR |
|
y=x0^x1 |
逻辑模块负责判断输入的数据是否满足预置条件,一般不会产生输出数据,而是根据运行后的成功或失败状态控制后续模块的触发。CraneScript中的预定义的逻辑模块如下:
| 模块名 | 定义 | 动作 |
|---|---|---|
| mdlTRUE |
|
i>0? |
| mdlFALSE |
|
i==0? |
| mdlEQ |
|
x0==x1? |
| mdlGT |
|
x0<x1? |
| mdlGE |
|
x0<>x1? |
CraneScript预定义了如下字符串处理模块:
| 模块名 | 定义 | 动作 |
|---|---|---|
| mdlString |
|
生成表示输入数值x的字符串 |
| mdlStringSize |
|
输出字符串长度 |
| mdlStringCHAR |
|
取字符串中第idx个字符 |
| mdlStringPushfilter |
|
将字符串sub拼接于y的尾部 |
| mdlStringPush |
|
x在前sub在后,拼接新字符串y |
| mdlStringSub |
|
复制输出从left开始至right结束的x的子字符串 |
| mdlStringFirstCHAR |
|
给出从start之后出现在x中的第一个出现的Cs中的任一字符及其位置 |
| mdlStringLastCHAR |
|
给出start之前在x中的最后一个出现的Cs中的任一字符及其位置 |
| mdlStringFirstSub |
|
给出start之后在x中的第一次出现子字符串sub的位置 |
| mdlStringLastSub |
|
给出start之前在x中的最后一次出现子字符串sub的位置 |
| mdlStringReplacefilter |
|
将y中从left到right间的子字符串替换成sub |
| mdlStringReplace |
|
复制字符串x,并将其中left以right间的子字符串替换成sub |
| mdlStringSplit |
|
使用子字符串SEG分割x,将分割的结果放入字符串数组aY中 |
| mdlStringLink |
|
使用分隔字符串SEG将字符串数组aX中的各字符串连接成一个字符串 |
| mdlStringUppercasefilter |
|
将字符串y转换成大写 |
| mdlStringUppercase |
|
复制字符串x到y,并将y转换成大写 |
| mdlStringLowcasefilter |
|
将字符串y转换成小写 |
| mdlStringLowcase |
|
复制字符串x到y,并将其转换为小写 |
CraneScript提供了一组数据操作模块:
| 模块名 | 定义 | 动作 |
|---|---|---|
| mdlArrayINITfilter |
|
初始化数据aX的数据空间 |
| mdlArraySize |
|
输出数组aX的长度 |
| mdlArrayItem |
|
输出aX[idx] |
| mdlArrayInsert |
|
将x插入数组aX的第idx个位置 |
| mdlArrayRemove |
|
从数组aX中移除第idx位的元素 |
| mdlArrayPush |
|
将x添加到数据aX的末尾 |
| mdlArrayPop |
|
移除数组aX的最后一个元素 |
CraneScript提供了一组用于系统标准输入输出操作的模块:
| 模块名 | 定义 | 动作 |
|---|---|---|
| mdlSTDIN |
|
从标准输入stdin中读入字符串in |
| mdlSTDOUT |
|
将字符串out输出到标准输出stdout |
| mdlGetCHAR |
|
从标准输入读取一个字符c |
CraneScript预定义了如下文件操作模块:
| 模块名 | 定义 | 动作 |
|---|---|---|
| mdlFileExist |
|
读取文件信息,包括大小,是否为目录,可读,可写等,若文件不存在则运行失败 |
| mdlFileOpen |
|
依据输入参数的设定执行打开文件操作,并返回文件句柄 |
| mdlFileClose |
|
关闭打开的文件 |
| mdlFileGetC |
|
从打开的文件中读取一个字符 |
| mdlFilePutC |
|
向打开的文件中写入一个字符 |
| mdlFileReadLine |
|
从打开的文件中读取一行(以\n结尾) |
| mdlFileWriteLine |
|
向打开的文件写入一行 |
| mdlFileReadArray |
|
从打开的文件中读取n个字符构成字符数组aY |
| mdlFileWriteArray |
|
将字符数组aX写入打开的文件 |
在处理虚拟类型端口的输入或输出数据时,有时需要知道其确切的数据类型。CraneScript提供了一组用于数据类型操作的模块:
| 模块名 | 定义 | 动作 |
|---|---|---|
| mdlType |
|
返回x的数据类型 |
| mdlTypeIS |
|
检测x是否为数据类型y |
| mdlTypeEQ |
|
比较x和y的数据类型是否相同 |
除去前述的常规基础模块,craneScript还提供了一组方便数据流编程使用的模块:
| 模块名 | 定义 | 动作 |
|---|---|---|
| Module |
|
预定义空模块 |
| mdlCmdLine |
|
用于读取主程序命令行参数 |
| mdlSystem |
|
调用系统运行cmd指令 |
| mdlPopen |
|
调用系统运行cmd指令,并给出其产生的输出y |
| mdlCACHE |
|
用于缓存数据x的模块,多用于使用控制流发送数据 |
| mdlSETfilter |
|
赋值操作y=x |
以上介绍了一些常用的预定义模块.更详细可参考download中的对应文件.
在craneScript中,没有定义诸如"if", "else", "switch", "for", "while", "until"等流程控制语句, 取而代之的是通过数据流+控制流的方式实现流程的分支和循环控制。
在数据流编程中,模块的输入数据决定的是模块是否可以运行的先决条件。当一个模块的输入数据全部到达时,该模块即开始运行。
特别地,当系统或程序启动时,那些不需要输入数据的模块首先进入运行状态。
当一个模块运行成功后,它产生的数据则会沿着数据流的方向流动到后续模块,成为后续模块运行的驱动力量。
而当一个模块运行失败时,因其无法供应出后续模块运行所需的数据,所以后续的模块将失去运行的机会。
这是一种数据驱动的或响应式的编程模式.
此段代码的输出如下:
Ax
BAx
CBAx
控制流是craneScript中定义的另一种用于驱动模块运行的方式。 控制流用于指示当一个模块运行成功或失败后哪些模块会得到运行,控制流不传输任何数据,仅用于控制流程的走向, 和数据流描述模块间的数据依赖相似,控制流首先可以用于描述模块间的时序依赖。 其次根据诸如逻辑模块运行后的状态,结合控制流可以实现流程的分支和循环管理。 另外,使用反向控制流也可以实现对模块的错误处理流程。
在上述代码中,若没有第7行的控制流代码时,本段代码的运行结果如下:
, 而当添加了第7行的控制流代码后,运行结果如下:
在数据流系统中,数据从原模块产生后,通过数据流涌动到下游模块。 有时在某些应用场景中,需要人为控制数据流动的时序,或数据流动的次数,这些时候需要使用系统模块"mdlCACHE"来达到控制数据流的目的。 "mdlCACHE"本身对输入数据不做任何处理,仅当进入运行状态后,将输入做为输出重新输出一次。
在上述代码中,使用一个打印模块p打印三个字符串,此时,需要控制字符串流入p的顺序,上述代码通过增加三个cache,并使用控制流来管理它们的时序依赖,实现了三个输出的协调和控制,使代码产生了如下稳定的输出:
line: 1
line: 2
line: 3
line: 4
CraneScript是一个新发展的语言,希望能够通过对数据流的深度实现来简化程序设计中复杂的结构和依赖问题。 同时通过对craneScript脚本的图形化表达,探索一种可视化的程序设计的可能。 CraneScript还处于一个需要不断完善的时期,如果有任何问题,欢迎通过公众号或email联系.
